There are no recommended prerequisites for this notebook.
# package imports (SHIFT + ENTER to run)
import numpy as np
import emcee
import corner
import matplotlib.pyplot as plt
from scipy.optimize import minimize
# dev note : needs exercises
Modelling (in development)#
Fitting a model to data requires some metric to determine how well a model fits. This is often referred to as the objective function or merit function. These functions provide a way of measuring agreement between the model instance and data.
Given a set of data points \((\boldsymbol{x},\boldsymbol{y}\pm \boldsymbol{\sigma_y})\) with Gaussian noise in the \(y\) direction only, the appropriate objective function is the chi squared (\(\chi^2\)) function,
\(\chi^2\) is related to likelihood by
The frequency distribution for each data point, \(y_i\), is Gaussian;
Imagine a data set is produced by the function \(f(x)= 0\). The data are collected with representative uncertainties; each data uncertainty perfectly represents the random noise for an observed data point. Say we have 6 data points and there uncertainties are \(\mathbf{\sigma_{y}}=(1.0, 1.2, 1.4, 1.6, 1.8, 2.0)\). The frequency distributions can be visualised as follows:
from matplotlib.colors import LinearSegmentedColormap
# Gaussian function to calculate frequency distribution values
def gaussian(x, mu, sigma):
return (1 / (sigma * np.sqrt(2.0 * np.pi))) * np.exp(-0.5 * ((x - mu) / sigma) ** 2)
plt.close(1)
plt.figure(1, figsize=(10, 6))
x = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0])
sigma_y = np.array([1.0, 1.2, 1.4, 1.6, 1.8, 2.0])
x_model = np.arange(8)
y_model = np.zeros_like(x_model)
# Plot vertical lines with Gaussian alpha values
y_range = np.linspace(-3.5, 3.5, 400) # Define the range for y values
# Create a 2D array for the heatmap
heatmap = np.zeros((len(y_range), len(x)))
# Fill the heatmap with Gaussian alpha values
for i, sigma in enumerate(sigma_y):
heatmap[:, i] = gaussian(y_range, 0, sigma)
# Create a custom colormap that goes from blue to white
colors = [(1, 1, 1), (0, 0, 0)] # Blue to white
n_bins = 100 # Number of bins in the colormap
cmap_name = 'blue_white'
cm = LinearSegmentedColormap.from_list(cmap_name, colors, N=n_bins)
width = 0.05
# Determine the min and max values for normalization
vmin = heatmap.min()
vmax = heatmap.max()
# Plot the heatmap
for i, xi in enumerate(x):
plt.imshow(heatmap[:, i:i+1], extent=[xi - width/2, xi + width/2, y_range[0], y_range[-1]],
aspect='equal', cmap=cm, origin='lower', vmin=vmin, vmax=vmax)
plt.colorbar(label='Probability Density')
plt.plot(x_model, y_model, 'k:', label=r'f(x) = 0')
plt.xlabel(r'$x$')
plt.ylabel(r'$y$')
plt.xlim(0, 7)
plt.title('Measurement Probability\n with 1-Dimensional Gaussian Errors')
plt.legend(loc='upper left')
plt.show()
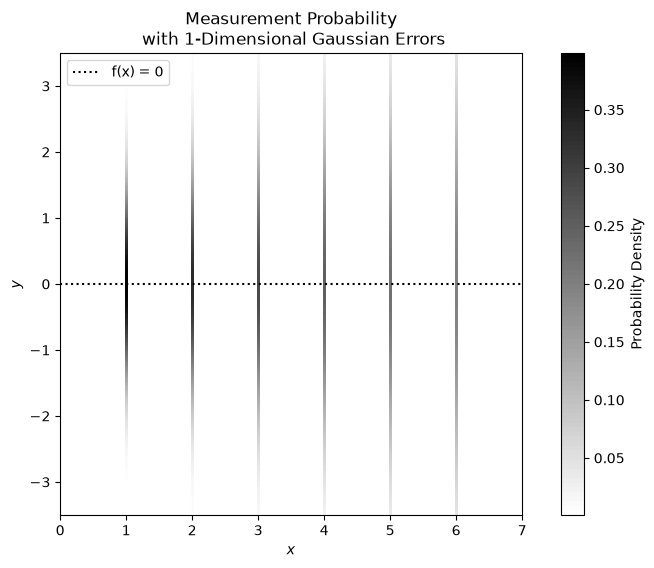
In the above plot, and the following plots like it, the gradiented regions are indicative of the relative probability of us measuring a given (\(x\), \(y\)) value. The darkest regions on the plot are the most likely measurement values.
But what exactly is a generative model? A generative model is a parameterised formula describing the statistical procedure for generating a given data set. Given a good generative model, the data set being fitted could reasonably be generated. Therefore, when fitting a model, one looks for the model parameters with the highest probability of producing the data set. This happens when the likelihood is maximised, or rather \(\chi^2\) is minimised.
Refer to Hogg, Bovy & Lang (2010) for a thorough breakdown on modelling terminology, guidance, and statistical premise.
Searching for the "best" model parameters can be done in many ways. One such method is the weighted linear regression method, described and used in the Single Lenses notebook, for deblending flux data. The choice of modelling method depends greatly on the data and the likelihood space.
In cases where both \(x\) and \(y\) uncertainties are significant, linear regression is an inappropriate choice of regression method. 2D uncertainties require 2D "distances," so orthogonal distance regression is a more appropriate choice. Colour-Colour relations between observatories are an example of fitting that uses orthogonal distance regression. See, for example, the Spitzer notebook (in preperation).
Considering our earlier \(f(x)=0\) model, if we give our \(x\)-data uncertainties of 0.35, our frequency distributions can be visualised as follows:
# Normalized 2D Gaussian function
def gaussian_2d(x, y, mu_x, mu_y, sigma_x, sigma_y):
return (1 / (2 * np.pi * sigma_x * sigma_y)) * np.exp(-0.5 * (((x - mu_x) / sigma_x) ** 2 + ((y - mu_y) / sigma_y) ** 2))
plt.close(2)
plt.figure(2, figsize=(10, 6))
x_points = np.array([1.0, 2.0, 3.0, 4.0, 5.0, 6.0])
sigma_x = 0.35
sigma_y = np.array([1.0, 1.2, 1.4, 1.6, 1.8, 2.0])
x_model = np.arange(8)
y_model = np.zeros_like(x_model)
# Define the range for x and y values
x_range = np.linspace(0, 7, 400)
y_range = np.linspace(-3.5, 3.5, 400)
X, Y = np.meshgrid(x_range, y_range)
# Create a 2D array to hold the combined heatmap
combined_heatmap = np.zeros_like(X)
# Calculate and sum the 2D Gaussian values for each point
for i in range(6):
Z = gaussian_2d(X, Y, x_points[i], 0.0, sigma_x, sigma_y[i])
combined_heatmap += Z
# Create a custom colormap that goes from white to blue
colors = [(1, 1, 1), (0, 0, 0)] # White to blue
n_bins = 100 # Number of bins in the colormap
cmap_name = 'white_blue'
cm = LinearSegmentedColormap.from_list(cmap_name, colors, N=n_bins)
# Plot the combined heatmap using imshow
plt.imshow(combined_heatmap, extent=[x_range[0], x_range[-1], y_range[0], y_range[-1]],
aspect='equal', cmap=cm, origin='lower')
plt.colorbar(label='Probability Density')
plt.plot(x_model, y_model, 'k:', label=r'f(x) = 0')
plt.xlabel(r'$x$')
plt.ylabel(r'$y$')
plt.xlim(0, 7)
plt.title('Measurement Probability\n with 2-Dimensional Gaussian Uncertainties')
plt.show()
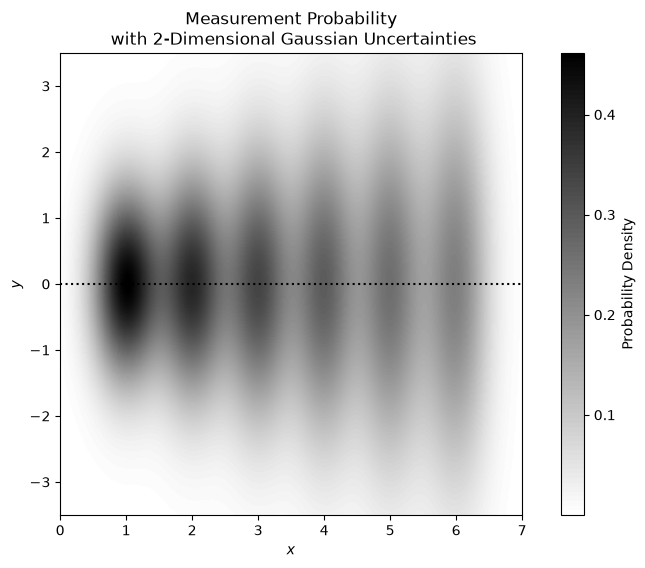
Were the data uncertainties negligible in both \(x\) and \(y\), we could use the much simpler, least-squares method to optimise our model parameters.
You may want to refer to the following videos for different explanations of these regression methods:
orthogonal distance regression (or this video about orthogonal distance regression with Statgraphics)
Or, if you have 40 minutes to spare and want to live in the magical land of no data measurement uncertainties, this is a good basic overview of regression.
There are thousands of good videos on least squares regression, because this is a commonly used machine learning technique. However, for machine learning purposes, modelling algorithms are usually designed for prediction power and implementation ease, rather than being driven by statistical robustness. The methods used for machine learning purposes can tend to play fast and lose with data science best practices. Finding good resources on data science approaches to regression can be challengeing nowadays, as accessible resources have become flooded with machine learning materials. We recommend you take care when learning data science techniques from sources that are not explicitly considering scientific purposes.
These examples have so far all been of a linear form. However, if the model was of a nonlinear form or we required bounds on our model parameters, the regression process would no longer be algebraic; we would require a numerical means of finding the merit function's minima. There are many methods for achieving this, and the choice of minimiser is often not of great importance for simple likelihood landscapes.
The parameter spaces of the multi-lens models are vast and the likelihood space is turbulent, making them very computationally expensive to explore. This turbulence is borne of the sharp magnification increases around caustics; a small change in model parameters and the resulting small shifts in alignment between source and caustics can results in large changes to the magnifications experienced by the source. This makes microlensing event modelling particularly challenging for what are usually well-performing minimisation methods. For this reason, we avoid "downhill" style methods in favour of random sampling (i.e. Monte Carlo methods; MC). Our modelling procedures tend to involve broad grid searches to determine plausible minima regions in the likelihood space (e.g. those shown in the Binary Lenses notebook), followed by the use of a Markov Chain Monte Carlo (MCMC) method, seeded by the plausible-grid results, for our minimisation.
MCMC#
MCMC is a subclass of the MC method.
MC methods use a means of generating random samples to perform simulations or integration. These methods can be used to solve deterministic problems, if the random samples are generated by a probability distribution; a prior (\(P(\Theta|M)\)). The meaningful result from an MC method comes not from an individual outcome, but from the statistical distribution of many samples; the posterior distribution (\(P(\Theta|D, M)\)). We can rewrite Bayes' theorem to better understand the role of data, \(D\), model, \(M\), and model parameter sets (solutions), \(\Theta\), in this method:
MCMC methods are also used to feel out the posterior distribution of a parameter through random sampling of the probability space. However, this process differs from general MC sampling in the sense that the best generative model is yet to be discovered. MCMC methods first perform a burn-in sequence to search for the most probable model parameters and then randomly sample the probability space to build the posteriors. This is where the "Markov chain" in MCMC comes in. Markov chain sampling is described as memory-less because the next step in the chain to be generated will always only be dependent on the current step. A proposed step in the parameter space will be accepted if it has a higher probability of generating the observed data than the currently accepted step, or it will be randomly accepted. This random acceptance is weighted so that the more probable steps are more likely to be randomly accepted.
MCMC is a beneficial method for modelling, as the inherent randomness allows for escape from the local optima that sometimes appear in stochastic algorithms. This is of great importance in the case of modelling multi-lens microlensing events, with their characteristic, poorly behaved probability space.
There are pre-existing python packages for the implementation of MCMC methods. These are useful because the optimisation of step proposal and acceptance algorithms are non-trivial. It is easy to say the sampler randomly accepts steps, but how often should that random acceptance occur and how big should our steps be so that we explore our space efficiently. And do those things need to change adaptively throughout the fitting and posterior sampling processes.
One such python implementation of MCMC is emcee (Forman-mackey, 2017). The algorithm employed by emcee implements a "state" of multiple "walkers." Each walker has their own MCMC chain, but the proposed steps are somewhat co-dependent between walkers. The ensemble samplings are also affine invariant by default, which is to say that the median of the proposed state is the same as the current state. The emcee package has excellent documentation and accompanying tutorials, which you can check out here.
Refer to the emcee documentation for more details on the sampling "moves."
Nested samples#
The algorithm often used for Bayesian inference of a Galactic model is Nested Sampling cite NestedSampling. Nested sampling is another commonly used model fitting method in the field of astrophysics. Feroz, Hobson, & Bridgescite (2008) presents the nested sampling algorithm as an efficient and robust alternative to Markov Chain Monte Carlo methods for astronomical data analyses. This fitting method is less useful for microlensing modelling because of the likelihood's stochasticity. However, it works well in the application of Galactic modelling, for which the probability distributions are smooth and well-behaved (as demonstrated in Galactic Models notebook).
Nested sampling is a statistical analysis algorithm used in Bayesian modelling, particularly in the context of model selection and parameter estimation. For example, \cite{Mukherjee2006} discusses how nested sampling can be applied to selection and inference of cosmological models. As with MCMC, nested sampling is built off of the principles of Bayes theorem. Nested sampling is also a Monte Carlo method, in that it relies on repeated random sampling to perform an integration.
In addition to parameter estimation and inference, nested sampling gives us a framework for comparison between models for which the \(\chi^2\) or \(\mathcal{L}\) are not strictly comparable. The evidence,
In nested sampling methods, the integral in the equation below is evaluated by breaking the prior volume up into concentric ``shells'', or high-dimensional contours, of iso-likelihood. Each shell has a probability, \(\lambda_i=P(V_i)\) and a volume \(dV\), and the evidence integral becomes
This problem can be re-framed again to create something even more computationally tractable:
The sampling criteria is therefore \({\{\Theta:\mathcal{L}(\Theta)>\lambda\}}\), with an increasing bound \(\lambda\). This integral can be approximated numerically by
The specific implementation of the nested sampling algorithm used for our Galactic model was the Dynesty package Speagle (2020), named such for its use of optionally dynamic nested sampling methods. These dynamic sampling methods are of particular importance when the goal is to sample a posterior, because they are designed to sample more frequently in high-likelihood regions, but are less important when the goal is to estimate the evidence, for which integration over the whole prior volume is required.
We can leverage this algorithm to make inferences from our lightcurve fits, based on a galactic model, in a manner resembling hierarchical modelling, which, put simply, means that we feed the posteriors of our lightcurve fit in as the prior for our Galactic model fit and the samples for our inference are drawn from the posterior distribution of the lightcurve fit;
For more on traditional hierarchical modelling, refer to Foreman-Mackey (2014) and their presentation of a hierarchical model, fit to exoplanet catalogue data.
Future additions to this notebook, in development:#
Uncertainty rescaling
Pruning outliers
Gaussian process (GP) modelling
Pixel-level decorrelation
Bayesian information criteria (BIC)
Next steps#
If you haven't already, try the Single Lens, Binary Lens, or Binary Source notebook, and test out some of this theoretical knowledge.